一个前端工程启动报错的问题
相关参考链接:
一:启动报错
在一个协作的前端工程,拉取代码之后,启动工程出现如下错误:
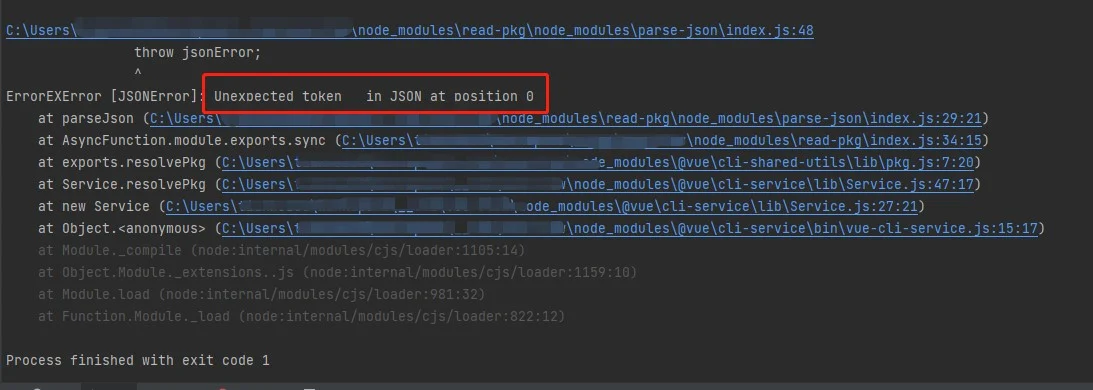
从错误日志看,是第一个字符JSON转换时就抛出错误
对比相关代码,并没有发现特殊的字符,甚至全选粘贴改成相同内容,仍然提示相同错误
直接替换文件,或者回退到老版本又正常
于是再对比差异,发现:
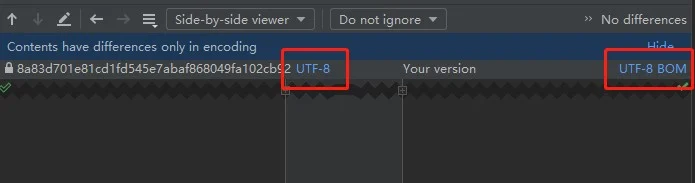
编码没问题,但多出来的 BOM是什么
二:字节顺序标记
2.1:BOM(byte-order mark)
是位于码点
中文维基百科U+FEFF的统一码字符的名称。当以UTF-16或UTF-32来将UCS/统一码字符所组成的字符串编码时,这个字符被用来标示其字节序。它常被用来当做标示文件是以UTF-8、UTF-16或UTF-32编码的标记。
【谷歌翻译】
在 1993 年初引入
W3CUTF-8之前,传输Unicode文本的预期方式是使用 16 位代码单元,使用称为UCS-2的编码,后来扩展到UTF-16。16 位代码单元可以用两种方式表示为字节:最高有效字节在前(big-endian)或最低有效字节在前(little-endian)。为了传达正在使用的字节顺序,在流的开头使用了U+FEFF(字节顺序标记)作为幻数,该幻数在逻辑上不是流所表示的文本的一部分。
2.2:UTF-8 中的 BOM
在
UTF-8中,虽然在Unicode标准上允许字节顺序标记的存在,但实际上并不一定需要。UTF-8编码过的字节顺序标记则被用来标示它是UTF-8的文件。它只用来标示一个UTF-8的文件,而不用来说明字节顺序。许多
Windows程序(包含记事本)会需要添加字节顺序标记到UTF-8文件,否则将无法正确解析编码,而出现乱码。然而,在类Unix系统中,这种做法则不被建议采用。中文维基百科
Unicode标准允许在UTF-8中使用BOM,但并不要求或推荐使用它。字节顺序在UTF-8中没有任何意义,所以它在UTF-8中的唯一用途是在开始时发出信号,表明文本流是用UTF-8编码的,或者表明它是从包含可选BOM的文本流转换到UTF-8的。
【谷歌翻译】
在
W3CUTF-8编码中,BOM的存在不是必需的,因为与UTF-16编码不同,字符中没有替代的字节序列。但是,BOM仍可能出现在UTF-8编码文本中,或者作为编码转换的副产品,或者因为它是由编辑器添加以将内容标记为UTF-8。在这种情况下,BOM通常称为UTF-8签名。
2.3:JSON 中的 BOM
由于在文件前插入了不可见但又实际存在的字符(\UFEFF),导致JSON无法正常解析字符串
这就是问题所在
三:解决方法
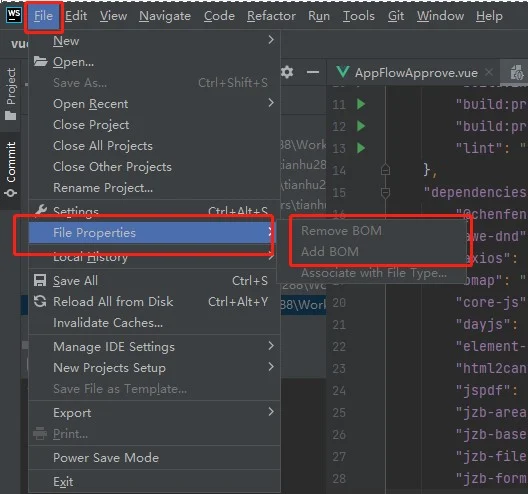
本人使用jetbrains系列软件开发,软件中自带“添加”/“移除”BOM的选项
不过这个问题也不是很罕见的问题了,估摸着大部分编辑器应该都自带该选项功能